A Short Guide to Translation Memory Management
How does Translation Memory Management work?
To understand how a translation memory is managed, we need to know the definition of Translation Memory. Translation memory is a database that continually captures translations as translators work on your projects for future use. It is created automatically by Text United. Meaning every time you translate content or have it translated by our human translators, a specific set of words is already being memorized by our system. All translation memories are saved to your private translation memory.
Translation Memory is an absolute essential in an operational toolkit for the localization field.
All the information captured in Translation Memory is based on the concept of a source sentence and a target sentence. If a new sentence comes in and the database finds a similar entry, it then shows the sentence to the translator as a proposal to use.
An advanced Translation Memory Management has been available in the Text United Desktop App forever. However, a more simplified and user-friendly version is now also available in the web app! Let us show you what the features are that make the Text United TM work like a dream!
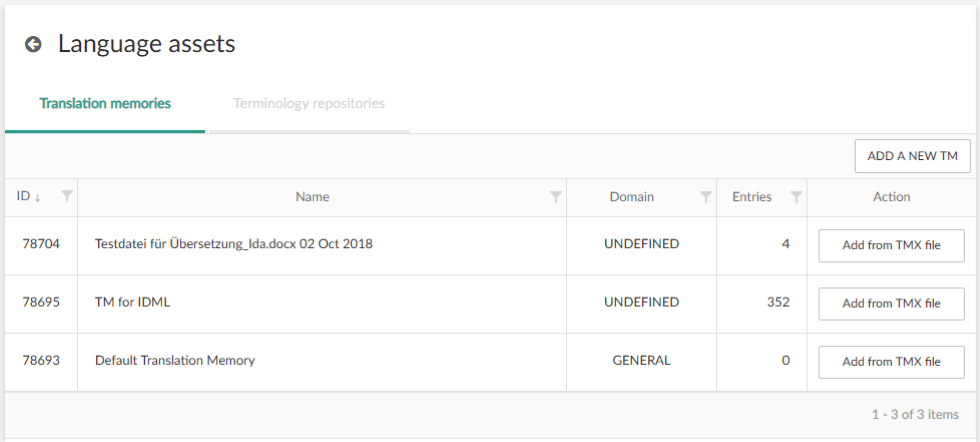
Language assets
Language assets on our portal are the place where the magic happens or as everyone else would say, where you can import/export and create your Translation Memory.
When you navigate from the user menu to Language Assets on our web portal, you will have a list of all your translation memories. As said, it’s possible to import .tmx files to an already existing Translation Memory or a newly created, empty one.
Once you have uploaded the .tmx file, select the corresponding language combination, and click on Import.TMX. Depending on the file size and the number of entries in the .tmx file, it may take a few moments for everything to be imported.
How to use an imported translation memory?
From this moment on, everything is automatic. Once you’ve created a new translation project, it automatically connects to the translation memories in the same language combination. The system will run an analysis of the translation project and match the new segments with existing segments in Translation Memory.
Depending on the degree of similarity, 100% identical segments will be put in place automatically (pre-translated), and anything below a 100% match will be available as a proposal that the translator can insert manually.
Translation Memory Alignment
Translation memory alignment is a way of making use of existing translation materials that will be a life and money saver for everyone who likes effective solutions. It’s a new feature that allows you to import two language files and convert them into translation units.
In short, TM alignment turns your existing translated material into assets that are then saved to a new or existing translation memory. It’s basically recycling content – in the smartest way imaginable!
How to use it? To start aligning your translated material, you will need two separate language versions of a file. One is the source (original) language, and the other will be the translated version (target). The TM Alignment tool consists of four main options:
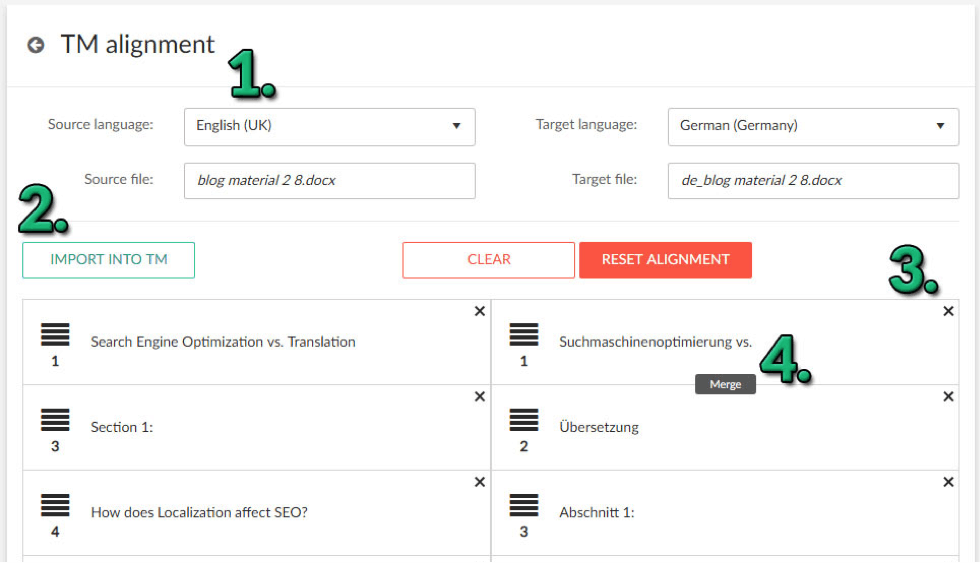
- Select source and target files and the corresponding source and target language
- Import into TM – once the alignment is done, use this option to import the translation units to a new or existing TM
- Delete a segment
- Merge segments
Once you click the Import into TM option, the aligned segments are saved to the chosen Translation Memory and are ready for use in new projects.
How does TM match the words?
Every time you upload a project, the system checks your translation memory for any similar or identical sentences that you’ve translated before. The degree of match is a percentage figure:
#1. Context Match – These are already translated sentences in the translation memory, which are in the same context as your new texts. The sentence needs to be a 100% match. The sentences before and after need to be the same as in the previous translation project. Context matches are usually larger parts of your document.
#2. 100% Match – If the content of a translation memory segment matches the source segment exactly, then it is a 100% match. To qualify as this, the entire content (all characters and character formatting) of both the source document segment and the translation memory segment must match exactly.
3#. Fuzzy Match – Everything below 100% is a fuzzy match.
Translation Memory can pre-translate 100% matches and find fuzzy matches among previous translations. Also, you won’t have to pay for the translation as if your material is translated from scratch. Instead, Text United will apply discounts for various levels of similarities! Expect a cost reduction of up to 40%.
Remember that using Translation Memory Management means that the more you translate, the less you work on the translation! Also, you never pay for the words already translated, so the more you translate, the less you pay. Go ahead and achieve more for less!
Comments
Post a Comment